Brett BarkleyI am a PhD candidate at the University of Texas at Austin advised by David Fridovich-Keil. My research is generously supported by Google. I am currently seeking industry Research Scientist roles focused on OOD detection, reinforcement learning, and robust integration of synthetic data into machine learning pipelines. If any of those align with a role you have, please reach out! I was previously employed by the Johns Hopkins Applied Physics Laboratory, where I worked on AI-based autonomy for aerospace systems. I have an MS in Aerospace Engineering from the University of Maryland where I was a research assistant under Prof. Derek Paley and member of the Collective Dynamics and Control Laboratory (CDCL). My area of specialization was flight dynamics, stability, and control and my thesis proposed a scalable cooperative autonomy framework for multi-agent aerial reconnaissance. CV / Email / Google Scholar / LinkedIn |

|
Research InterestI study how to make synthetic data more reliable and effective for scaling AI training pipelines. My work challenges the assumption that even well-structured synthetic data is always beneficial, showing that, without careful integration and diagnostics, it can degrade performance or distort learning dynamics. I develop methods for structured data augmentation, failure analysis, and algorithmic repair to make synthetic data more trustworthy. Recent projects include empirical studies exposing structural flaws in model-based RL pipelines built on synthetic rollouts, time-symmetric data augmentation in sequential decision-making problems, and ongoing development of diagnostic tools for out-of-distribution detection using diffusion models, aimed at identifying when synthetic data distributions diverge from trusted real-world contexts. |
News
|
|
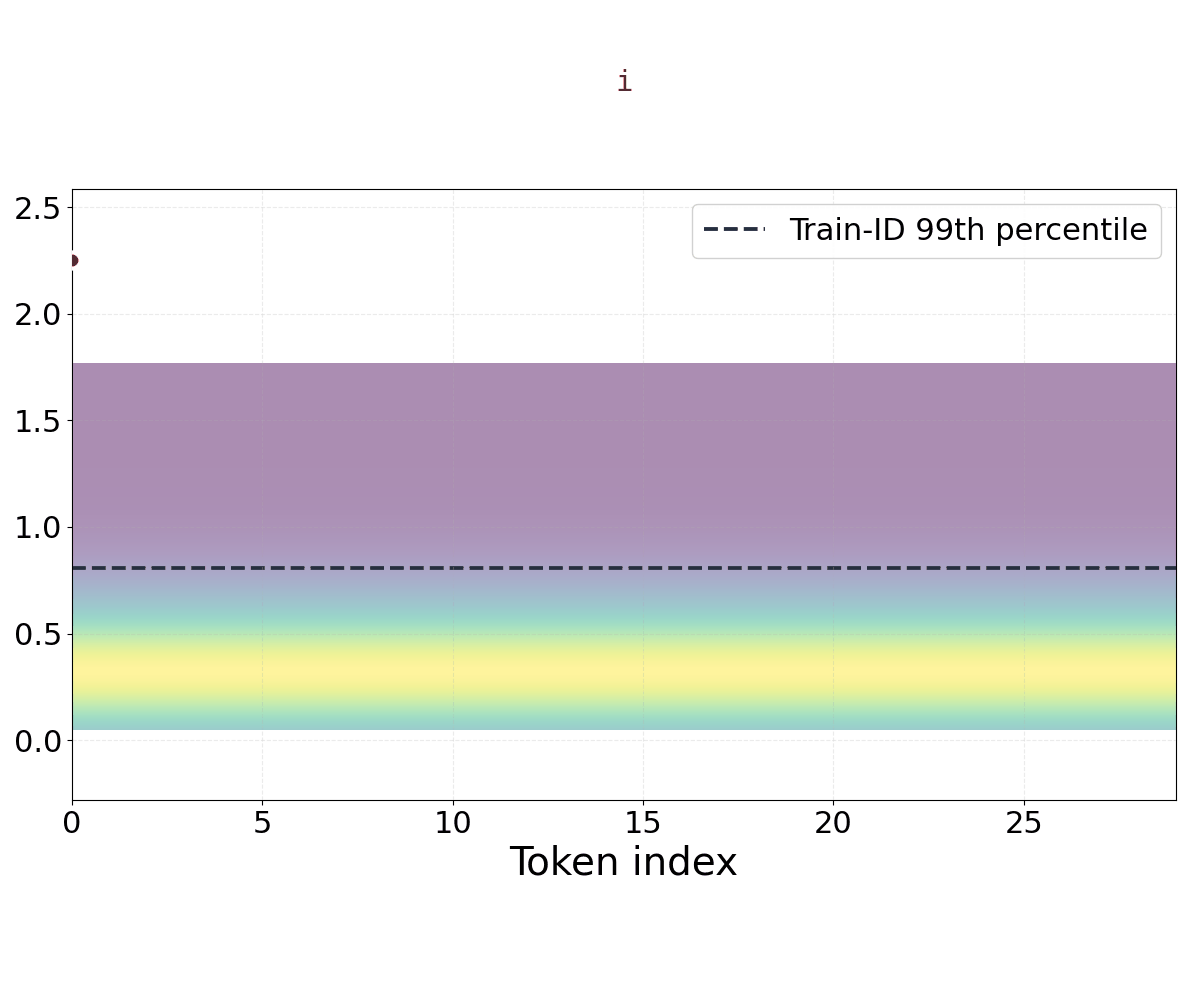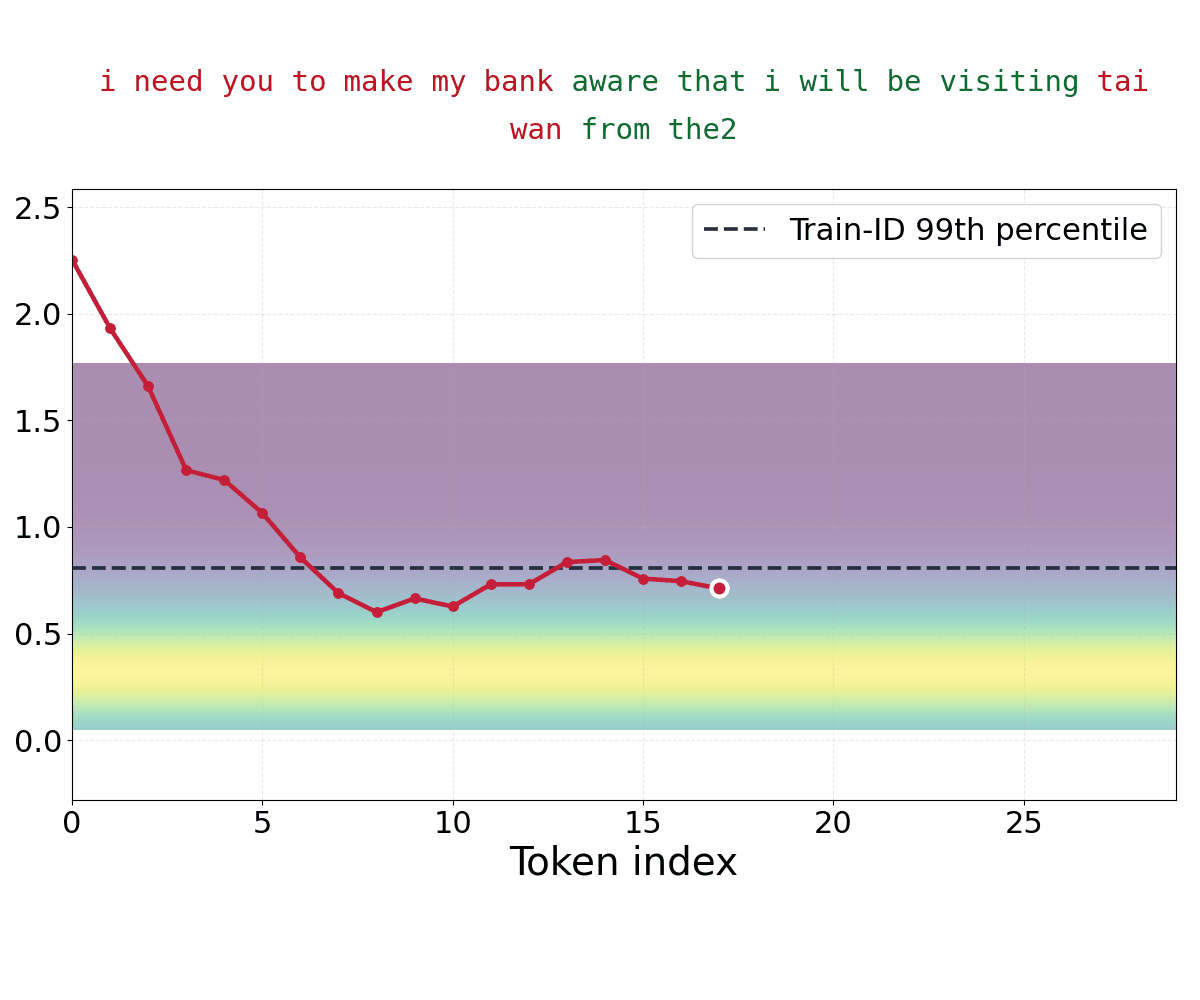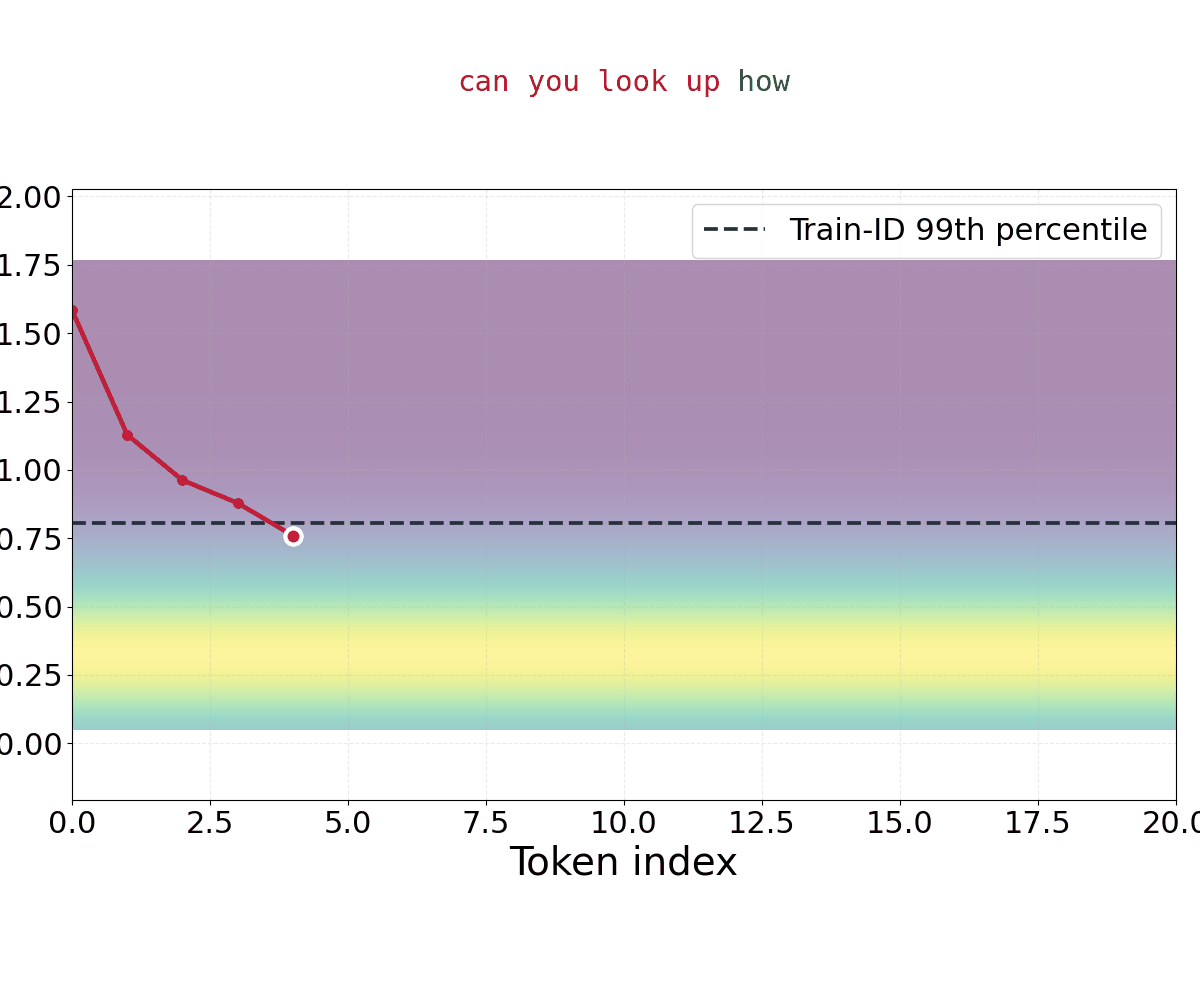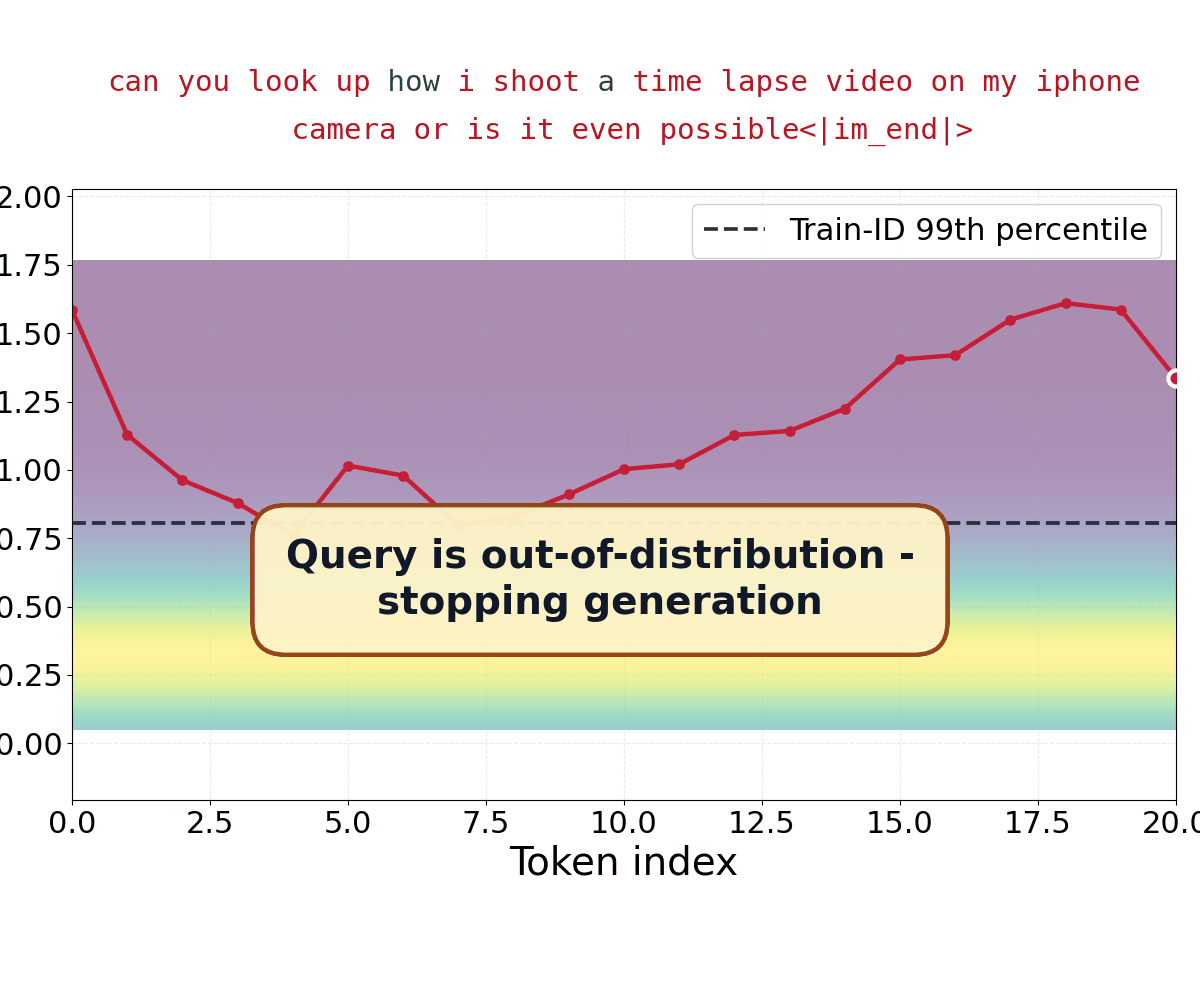
Scaling Pretrained Representations Enables Label-Free Out-of-Distribution Detection Without Fine-Tuning
Brett Barkley, Preston Culbertson, David Fridovich-Keil Preprint, 2026 arXiv We show that label-free OOD detection is increasingly a property of representation geometry rather than detector complexity. |
|
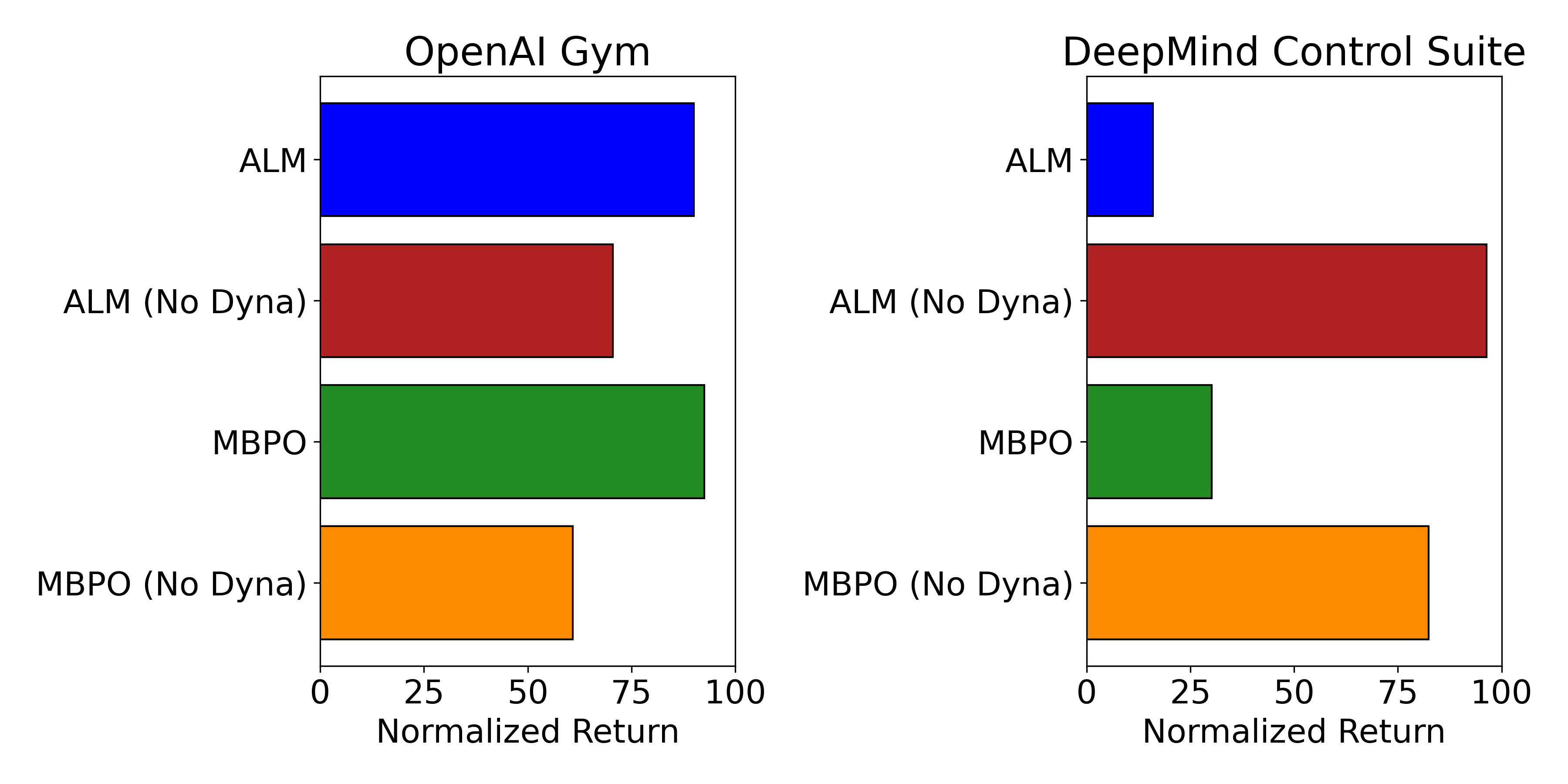
A Forensic Analysis of Synthetic Data in RL: Diagnosing and Solving Algorithmic Failures in Model-Based Policy Optimization
Brett Barkley, David Fridovich-Keil Preprint, 2025 arXiv We identify when, where, and why synthetic rollouts destabilize MBPO, and propose simple remediations that allow it to perform exceptionally well in environments where it previously could not improve beyond a random policy. |
|
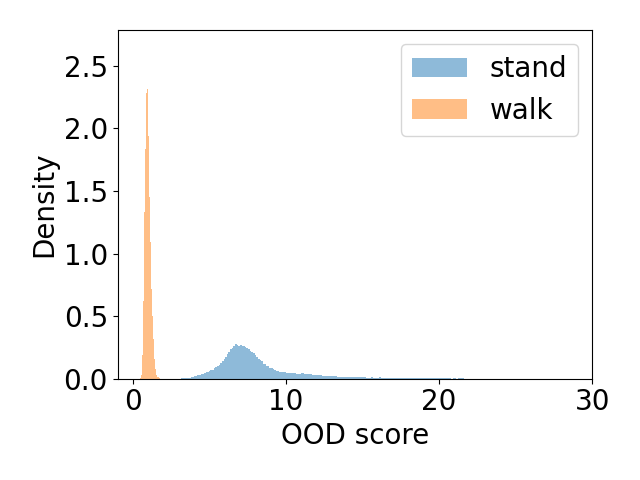
SCOPED: Score–Curvature Out-of-Distribution Proximity Evaluator for Diffusion
Brett Barkley, Preston Culbertson, David Fridovich-Keil ICLR, 2026 arXiv We introduce a diffusion-based OOD detection method using score curvature to measure typicality, enabling fast, reliable detection across vision and RL datasets. |
|
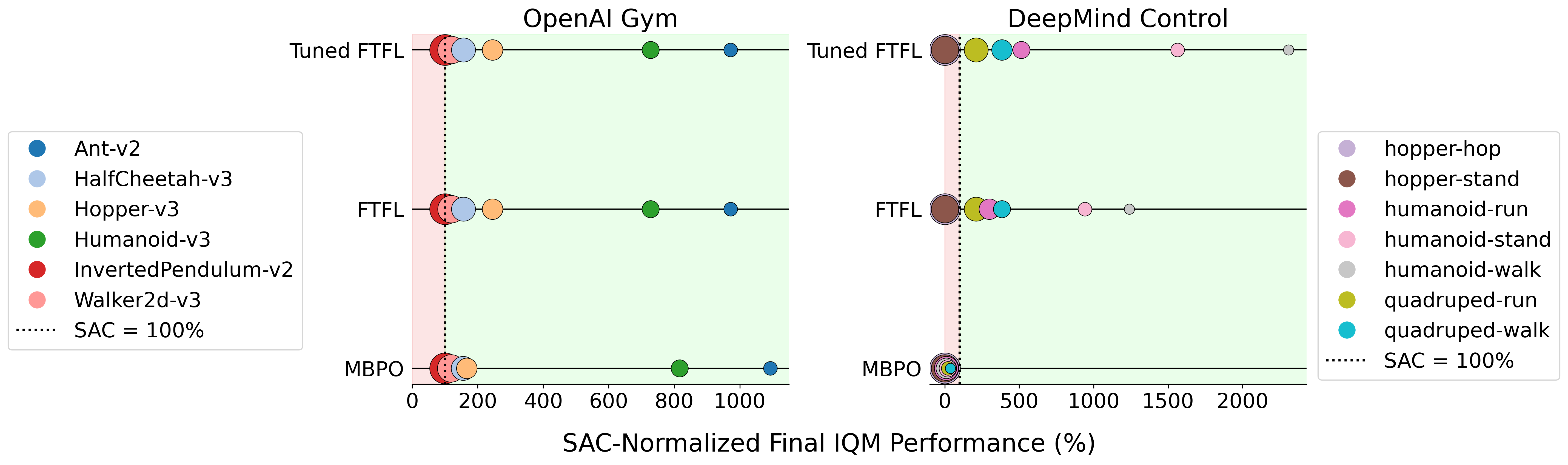
Stealing That Free Lunch: Exposing the Limits of Dyna-Style Reinforcement Learning
Brett Barkley, David Fridovich-Keil ICML, 2025 arXiv/ Code We show that synthetic rollouts in model-based RL can actually harm performance, identifying fundamental instabilities in Dyna-style methods. |
|
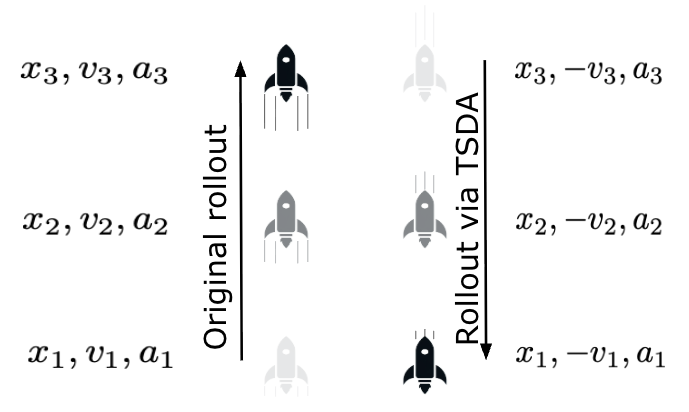
An Investigation of Time Reversal Symmetry in Reinforcement Learning
Brett Barkley, Amy Zhang, David Fridovich-Keil L4DC, 2024 arXiv We explore the role of time symmetry in RL algorithms and propose new augmentation strategies that exploit this structure. |
|
Design and source code adapted from here |